Cramped: Part 1 - initial-architecture
@kjuulh2023-09-10
In this post I will dig into the architecture of Cramped. I will start by
setting the most immediate requirements for me to get started on actually
selecting components, and then finally produce a diagram of the most major
components and their communication patterns and dependencies.
In total after this post, we should have a good idea of why cramped exists,
which components to develop, which metrics to select for, and how the components
should be domain sliced, if they were developed by independent teams (All of
this will be developed by me however).
The overall process will be somewhat informal, and won't stick to industry standard enterprise architect bullshit; mainly because I despise it, and have not gotten a good result of doing it once.
Requirements
This will be a little bit special, as I will act as both the stakeholder, and the developer. But I am pretty hard on myself on what I want, so this should be a sinch. I also tend to not have any respect for future Kasper, so this should be fun.
- The system should handle homogenous events, such as IoT data, application events, and such.
- The system should be queriable for long time analytics (3 month history), median 95th tail latency of 30 seconds
- The system should be used for real time analytics with a refresh window of 1 minute
- The system should be exposeable via apis, for third party services
- The system should be run on multiple hosts
- Each part of the system should be deployable on its own
- As a backend engineer, the only thing I should provide is a schema for my event, and the upload of the data
- As a data ops guy the only thing I is building my component, and hook it up in a central repository for configuring where in the pipeline it goes.
- The service should be versioned, so that schemas can evolve and old snapshots can be compacted, to remove potential PII
- As a data engineer, I don't want to deal with tuning the JVM, as such alternatives should be found, this is also to not rely too much on the knowledge I've already got doing this.
These requirements are pretty loose. we'll dig into how to actually go about achieving these, as well as defining metrics for the ones that need it.
Architecture
The backend services already exist, and looks like this:
Backend
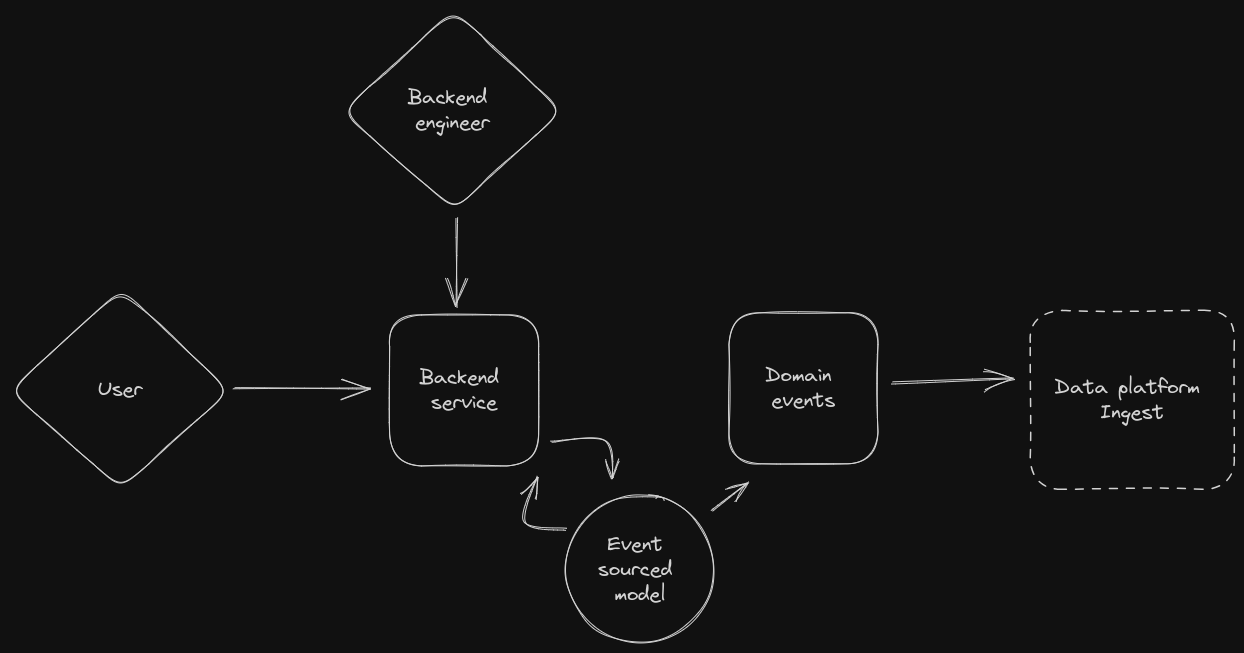
What happens here is that we have variety of business services, which are used
and serviced by either a User, or an engineer specifically. All the models are
event sourced using a home built library (something like eventstore, could
also be used). Some of these events are then republished as domain events, which
can be used by other services through a common communication layer, which I will
share later.
These domain events are what ends up in the data platform.
Internet of Things
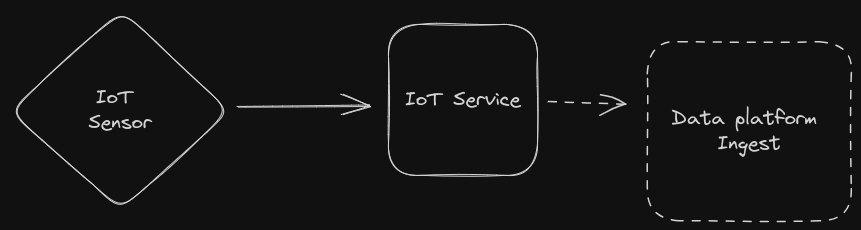
Like the backend services, we have IoT services for various things, such as
storing measured data, or controllers for doing various things. Most of these
are called or calls home assistant directly. A Domain event is created if
needed, which end up in the data platform.
Existing communication layer
Services communicate with each other through both synchronous and asynchronous messaging. For synchronous calls protobuf, json and capnp is used. json for the frontend, usually through graphql, internally a variety of protobuf (if using go), or capnp if using rust. Usually I don't mix go and rust services in a single domain, as such this fits fine with my progressing into adopting capnp.
For asynchronous I've developed an in-house format based on capnp, which travels over a database (using an outbox pattern), and then finally captured by a NATS stream.
It sort of looks like this: written in json here to be more easily understood, as capnp is a binary format
{
"event": "user.identity.created",
"sequence": 142,
"metadata": {
"published": "<some timestamp>",
"domain": "user",
"entity": "identity",
"name": "created"
// "..."
},
"content": {
"userId": "<some-uuid>",
"email": "<some@email>",
"name": "<some full name>"
}
}
A schema will be supporting this data, which will also be ingested and applied later down the line. It will also contain information on how to handle the contents of the events, some fields may be communicated, in which the dataplatform really, really need to be careful in handling.
@<id>;
using Metadata = import "cramped.metadata.capnp";
struct Event {
userId @0 :Text $Metadata.id;
email @1 :Text $Metadata.hash.sha256;
name @2 :text $Metadata.tokenize;
}
These annotations can evolve as well. If a change happens to a schema, the datalake should automatically produce a new version of the data with the changes. This may be rolling over all the data, and applying transformations required.
These messages are sent over NATS, the event type is used as the nats routing key, though format changed to its specific flavor.
Data platform ingest
The data platform ingest pretty much consists of two parts. Handling events with and without a schema / schema application failed.
An event will flow through a NATS global event consumer, which will then get a schema applied while being transported to a data fusion pipeline (Apache spark alternative)
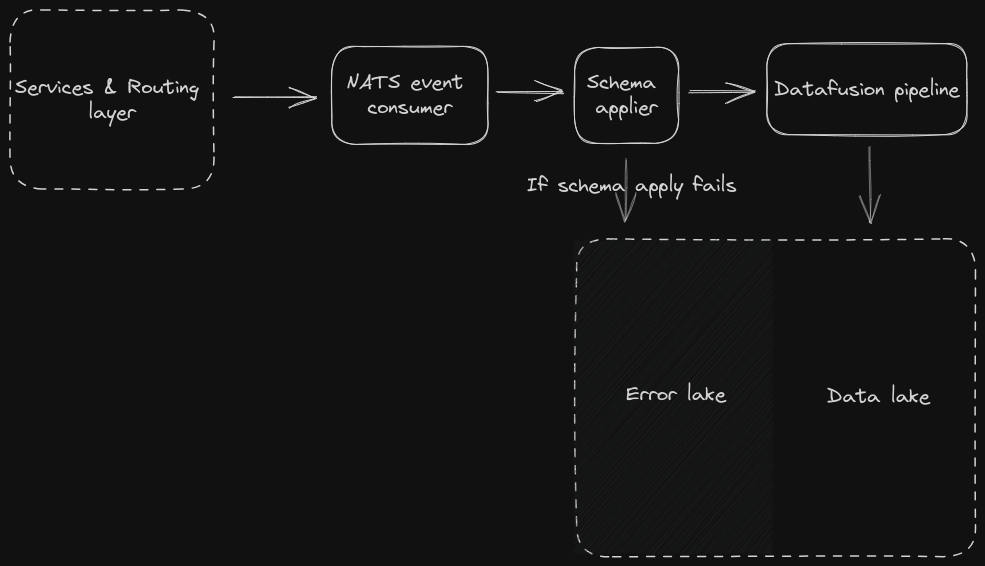
This is not very different than normal data ingestion pipelines, though without Kafka and Spark. If a schema application fails, or cannot be found, it will be stored in the Error lake, otherwise it will be put in the data lake. through data fusion.
Data fusion works like a sort of orchestrator, so a variety of jobs can be scheduled on it for doing various transformations on the data lake, be transforming the data into parquet, iceberg or something else.
It may also be used for back-filling from the error lake, or versioning / re-partitioning the data lake.
Data lake(house)
The idea behind the data lake is to make it a queryable place, with up to up to date base models, and integrated transformations by the users. It includes support for compaction, versioning, scale out queries, transformations and much more.
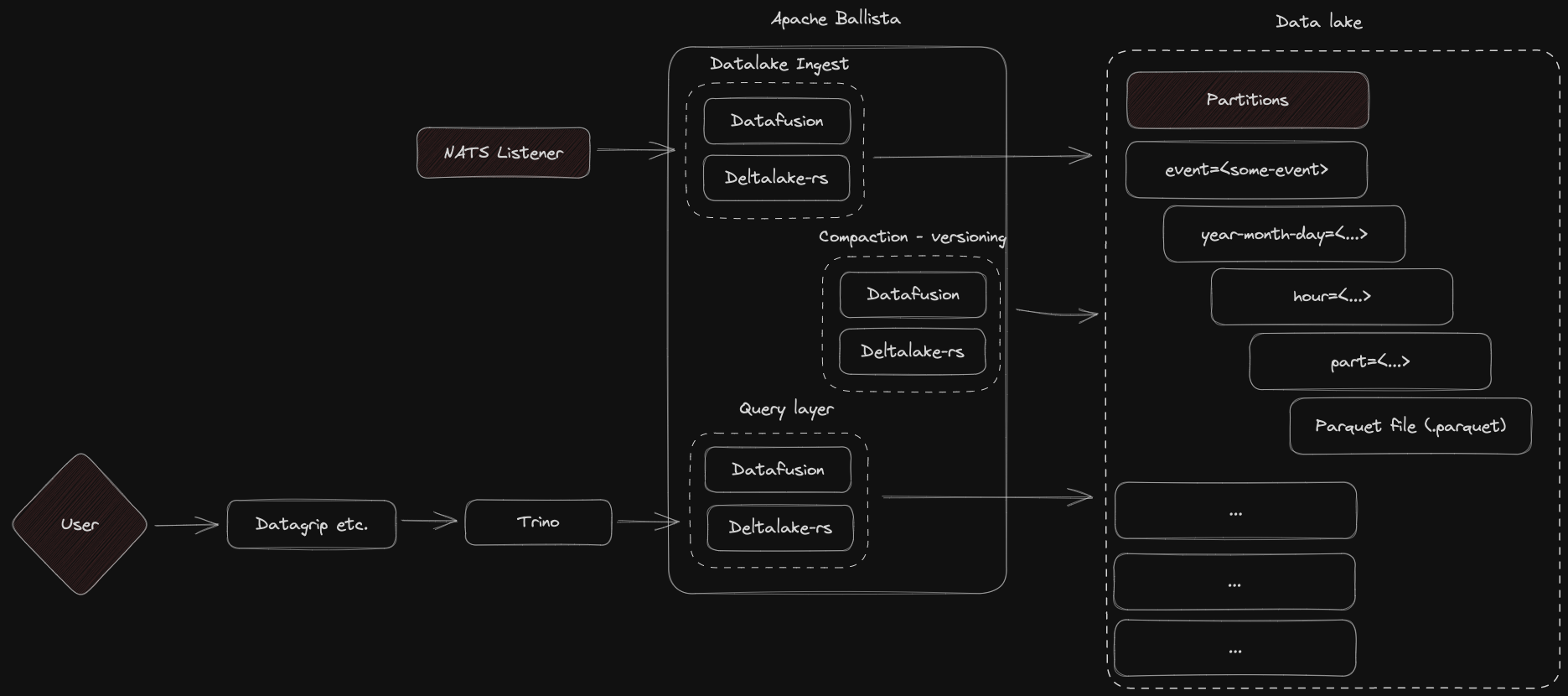
In here we see the data entering the system from the NATS listener, it will pull out data from the nats stream and ingest them into the datafusion pipeline running in Apache Ballistra (Rust based Spark like thingy). Using deltalake as the query and application layer, we're able to place data in the data lake in a streamed approach.
Other jobs are run as well, for example compaction and versioning, for automatically optimizing the query layer, as well as removing sensitive data marked during ingestion.
A user can then query the lake directly using a regular workflow built on deltalake for querying, the sql format is ANSI SQL, as it is queried through Trino (distributed sql).
Realtime analytics
I will have a need for realtime aggregations, as such a bunch of allowed transformations should end up in clickhouse for rapid querying.
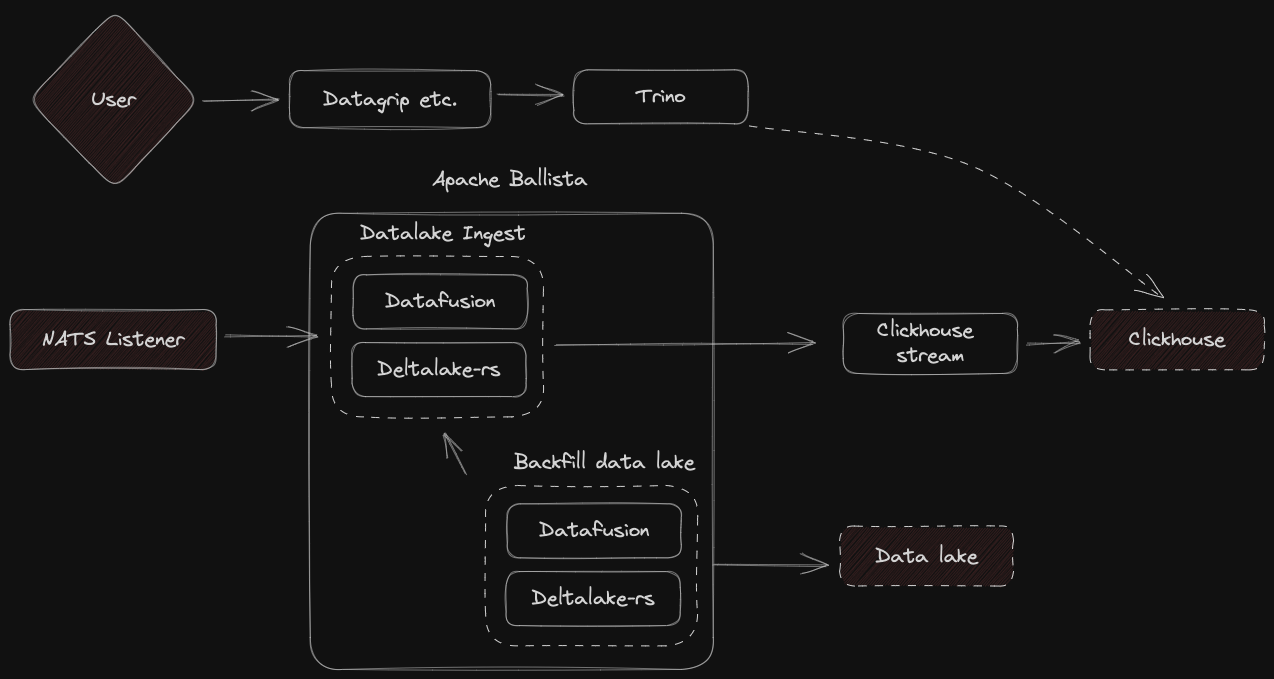
Much of the same architecture from before is used (See datalake section),
however, we also put data in clickhouse, this is to enable rapid querying on a
small subset and possibly sliding window of aggregations. Trino also
integrates with clickhouse for querying.
Ingest sends streamed data in much smaller batches, but still have the same guarantees for schema application, as that is done in an earlier step. A backfill is run regularly to fetch certain transformations, or restore precise data consistency in the clickhouse stream. This means that technically clickhouse can be removed entirely, and restored to a fresh instance and still get the same data